

Protein Data Bank Archives its 100,000th Molecule Structure
International research archive co-hosted by SDSC doubles in size since 2008
Published Date
By:
- Jan Zverina
Share This:
Article Content
As the single worldwide repository for the three-dimensional structures of large molecules and nucleic acids that are vital to pharmacology and bioinformatics research, the Protein Data Bank (PDB) recently archived its 100,000th molecule structure, doubling its size in just six years.
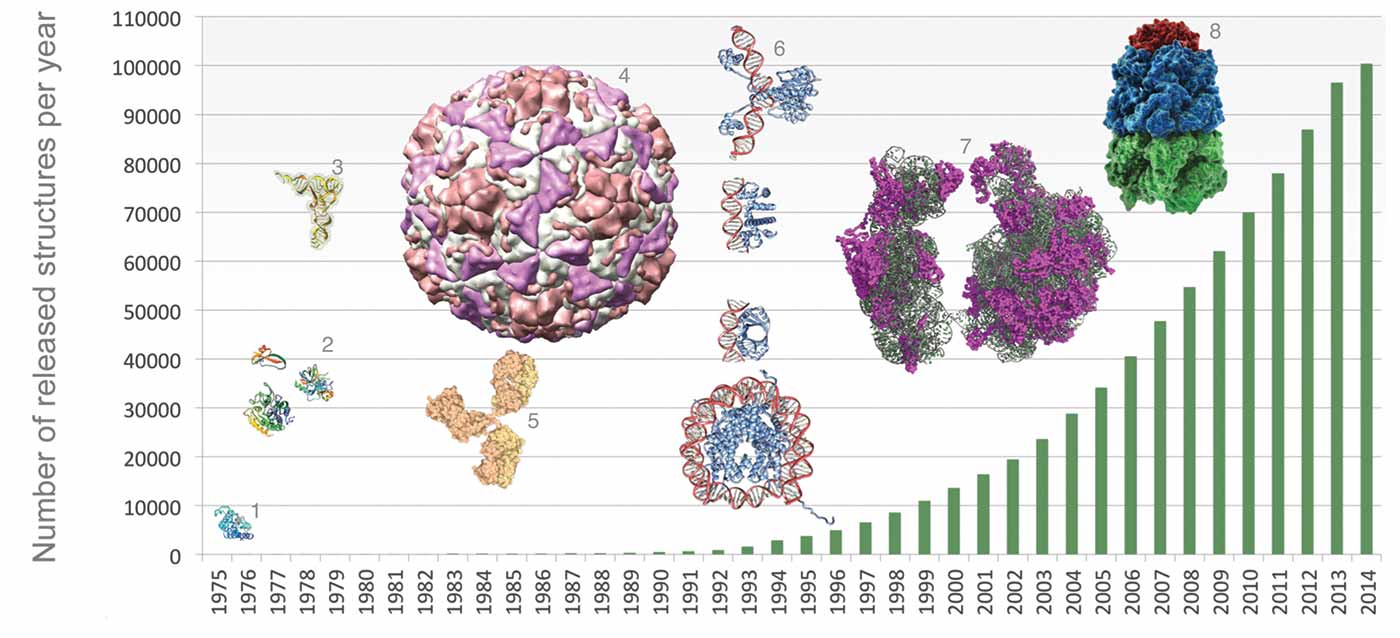
The number of structures available in the PDB per year, as of May 14, 2014. Highlighted examples include myoglobin (1; PDB ID 1mbn), the first structure solved by X-ray crystallography, and small enzymes (2; top: 4pti, bottom right: 2cha, bottom left: 3cpa). As technologies developed, the archive grew to host examples of tRNA (3; 6tna), viruses (4; 4rhv), antibodies (5; 1igt), protein-DNA complexes (6; top to bottom, 1j59, 1tro, 2bop, 1aoi), ribosomes (7; 1fjg, 1fka, 1ffk), and chaperones (8; 1aon). Image courtesy of wwPDB.
Four data centers, including one co-located at Rutgers, The State University of New Jersey; and the San Diego Supercomputer Center (SDSC)/Skaggs School of Pharmacy and Pharmaceutical Sciences at the University of California, San Diego, support online access to the three-dimensional structures of biological macromolecules that help researchers understand many facets of biomedicine, agriculture, and ecology, from protein synthesis to health and disease to biological energy.
Established in 1971, this central, public archive of experimentally-determined protein and nucleic acid structures has reached this critical milestone thanks to the efforts of structural biologists throughout the world.
“The PDB is a critical resource for the international community of working scientists which includes everyone from geneticists to pharmaceutical companies interested in drug targets,” said Nobel Laureate Venki Ramakrishnan, of the MRC Laboratory of Molecular Biology in Cambridge, England, in a wwwPDB release marking the milestone this week.
“SDSC has provided safe haven for the PDB since it arrived at UC San Diego in the late 1990s, along with Phil Bourne,” said SDSC Director Michael Norman. “It was the project that initially got us involved in data science, and it remains an important element in our ‘Big Data’ strategy. I congratulate the PDB project for their success and achieving this significant milestone.”
Bourne recently joined the National Institutes of Health as the Associate Director for Data Science. He formerly was Associate Vice Chancellor for Innovation and Industry Alliances, a Professor in the Department of Pharmacology and Skaggs School of Pharmacy and Pharmaceutical Sciences at UC San Diego, an SDSC Distinguished Scientist, as well as Associate Director of the RCSB (Research Collaboratory for Structural Bioinformatics) PDB.
Function Follows Form
In the 1950s, scientists had their first direct look at the structures of proteins and DNA at the atomic level. Determination of these early three-dimensional structures by X-ray crystallography ushered in a new era in biology—one driven by the intimate link between form and biological function. As the value of archiving and sharing these data was quickly recognized by the scientific community, the PDB was established as the first open access digital resource in all of biology by an international collaboration in 1971, with data centers located in the U.S. and the United Kingdom.
Among the first structures deposited in the PDB were those of myoglobin and hemoglobin, two oxygen-binding molecules whose structures were elucidated by Chemistry Nobel Laureates John Kendrew and Max Perutz. With this week's regular update, the PDB welcomes 219 new structures into the archive. These structures join others vital to drug discovery, bioinformatics, and education, for a total of 100,147 entries.
The PDB releases approximately 200 new structures to the scientific community every week. The resource is accessed hundreds of millions of times annually by researchers, students, and educators intent on exploring how different proteins are related to one another, to clarify fundamental biological mechanisms and discover new medicines.
Future Challenges
As the scientific community eagerly awaits many more structures to be deposited in the PDB along with the invaluable knowledge these additions will bring, the increasing number, size, and complexity of that data constitute major challenges for the management of the archive. The wwPDB earlier this year launched a new Deposition and Annotation System designed to meet the evolving needs of the scientific community over the next decade. Since its initial launch, more than 750 X-ray crystallographic structures from 30 countries have been deposited using the new system.
Share This:
You May Also Like


Stay in the Know
Keep up with all the latest from UC San Diego. Subscribe to the newsletter today.